Computer Vision Lab
University of Virginia
For the lastest publications, visit Zezhou's homepage.
Label-efficient Visual Understanding

The cost of collecting human annotations is a significant barrier in many vision tasks. For example, annotating the landmarks or semantic parts of an object is much more time-consuming than categorizing the image; annotating the 3D pose of an object is often done by reasoning with 3D model's projection to the 2D image; annotating objects with fine-grained labels (e.g. Grasshopper sparrow vs. Lincoln's sparrow) requires strong domain-specific expertise. In addition, labeling without clearly defined protocols leads to a variation in labeling styles of different annotators, which can make subsequent learning harder.
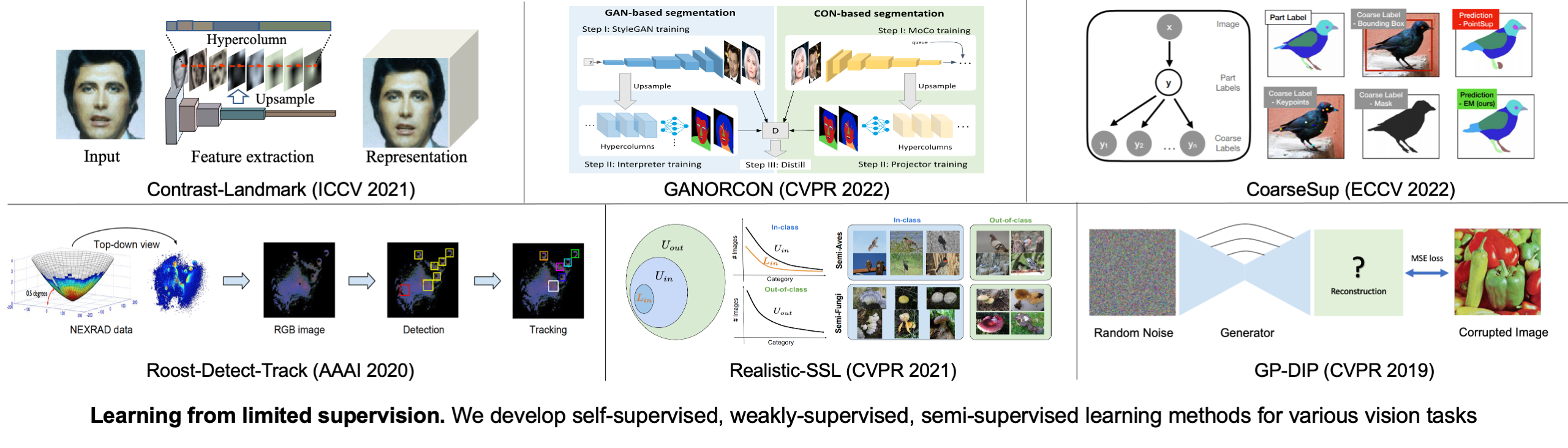
To minimize the annotation cost, one of our research goals is to develop learning algorithms in the context of different vision tasks to reduce the cost of supervision and allow learning from different labeling styles.
List of publications:
- Saha et al. Improving Few-Shot Part Segmentation using Coarse Supervision. ECCV 2022
- Saha et al. GANORCON: Are Generative Models Useful for Few-shot Segmentation? CVPR 2022
- Cheng et al. On Equivariant and Invariant Learning of Object Landmark Representations. ICCV 2021
- Su et al. A Realistic Evaluation of Semi-Supervised Learning for Fine-Grained Classification. CVPR 2021
- Cheng et al. A Bayesian Perspective on the Deep Image Prior. CVPR 2019
Reconstruct and Recognize Anything in 3D

Our research goal in this thrust is to build a system capable of holistic 3D scene understanding and reconstruction. We humans have a holistic understanding of the 3D visual world --- we can easily perceive the object categories, their location, and shapes and even interact with them. This is a fundamental capability required of intelligent agents to navigate and interact with the 3D environment. Besides this, reconstructing a realistic and immersive virtual 3D world has many applications in VR/AR, robotics, and autonomous driving.
However, such holistic 3D scene understanding and generation are beyond the current state-of-the-art computer vision systems. There are several critical challenges to address. First, scene understanding and 3D reconstruction are usually studied separately, which we believe should be integrated in a way that they are mutually beneficial; Second, compared to 2D tasks, the lack of human annotations becomes even more problematic for 3D tasks (e.g., 3D object detection and segmentation, 3D pose estimation); Third, unlike 2D images, 3D models are expensive to acquire, especially for deformable objects such as animals;
We aim to build a system to holistically understand and reconstruct the 3D scene with minimal human supervision.
List of publications:
- Cheng et al. LU-NeRF: Scene and Pose Estimation by Synchronizing Local Unposed NeRFs. ICCV 2023
- Cheng et al. Accidental Turntables: Learning 3D Pose by Watching Objects Turn. ICCV-W 2023
- Cheng et al. Cross-Modal 3D Shape Generation and Manipulation. ECCV 2022
Computer Vision + X
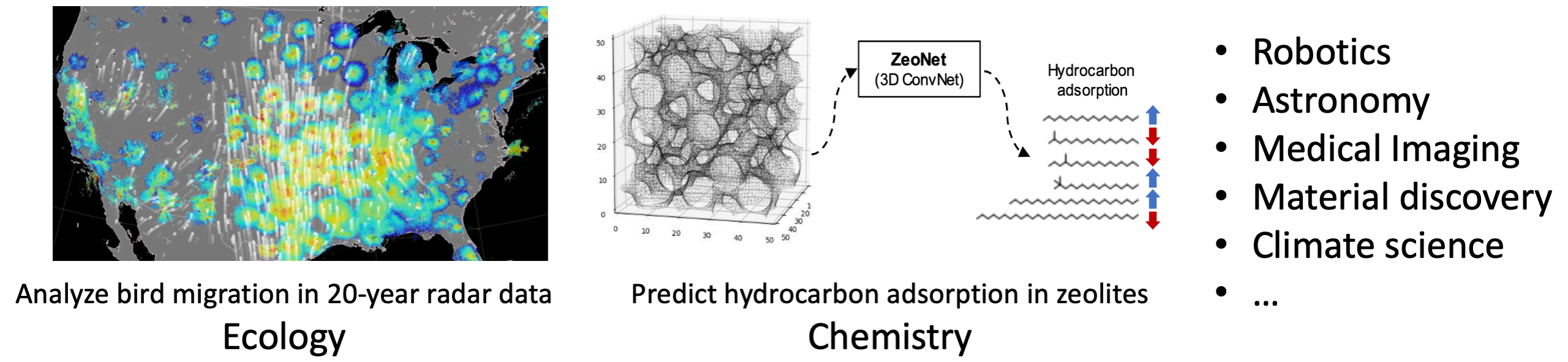
Recent years have witnessed significant advancements in computer vision, with its applications extending across a broad range of industries and research areas. In our previous research, we have leveraged these advancements to develop efficient computer vision models for diverse fields. For instance, we analyzed two decades of extensive radar data to study bird migration patterns in ecology and developed machine learning models to predict hydrocarbon adsorption in zeolites for chemical research.
We are enthusiastic about building multidisciplinary collaboration and promoting the application of AI across various scientific fields including but not limited to robotics, natual language processing, climate change, and material discovery. Welcome to talk with us and explore potential cross-field collaboration opportunities!
List of publications:
- Perez et al. Using spatio-temporal information in weather radar data to detect and track communal bird roosts. Remote Sensing in Ecology and Conservation. 2024
- Liu et al. ZeoNet: 3D convolutional neural networks for predicting adsorption in nanoporous zeolites. Journal of Materials Chemistry A, 2023
- Zhao et al. A Semi-Automated System to Annotate Communal Roosts in Large-Scale Weather Radar Data. NeurIPS Computational Sustainability: Pitfalls and Promises from Theory to Deployment, 2023
- Belotti et al. Long-term analysis of persistence and size of swallow and martin roosts in the US Great Lakes. Remote Sensing in Ecology and Conservation, 2022
- Deng et al. Quantifying Long-term Phenological Patterns of Aerial Insectivores Roosting in the Great Lakes Region using Weather Surveillance Radar. Global Change Biology, 2022
- Cheng et al. AI for conservation: learning to track birds with radar. ACM XRDS 2021
- Cheng et al. Detecting and Tracking Communal Bird Roosts in Weather Radar Data. AAAI 2020